


上周二,Nvidia的股价再次超越苹果,成为环球最有价值的公司,继本年6月创下雷同记录后,再度迎来光泽时刻。在昔时两年中,凭借GPU的矫捷算力,Nvidia在AI期间可谓答允无尽,芯片性能控制攀升,取得了宏大的阛阓得胜。但是,不得不指出的是,尽管GPU时刻赶快发展,仍有一些短板时刻正在成为英伟达发展的隐性挫折,影响着其进一步的打破。
大喊大进的GPU
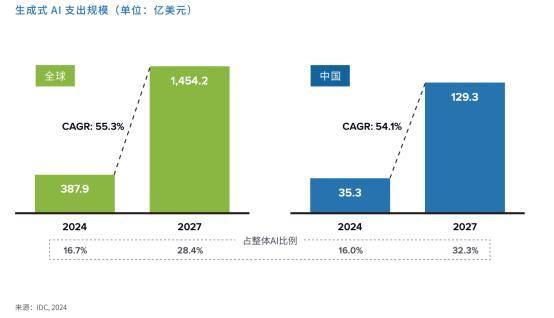
近一两年来,咱们不错看到GPU的速率迭代相当快,背后很大的要素是生成式AI(大模子)的爆发式增长。IDC预测到2027年,环球生成式AI阛阓边界将攀升至1454亿好意思元,中国阛阓的投资也将达到129亿好意思元,IDC指出,这一发展趋势的能源源自时刻迭代的加速、应用领域的拓宽,以及企业对 AI 翻新驱动的不懈参预。
算力是生成式AI发展的物理基础,GPU是加速筹划的主要器具。要已毕大模子的打破,就需要大幅提高GPU的性能。GPU咫尺正进入一种“自我加速”的发展模式。英伟达和AMD等厂商濒临着宏大的阛阓压力,它们必须控制在硬件联想上弃旧容新,力务已毕每年一个小迭代、每两年一个大迭代,才调满足这些需求。即使Hopper H100 GPU 平台是“历史上最得胜的数据中心处理器”,但黄仁勋在本年的Computex主题演讲中说到,Nvidia也必须链接勤奋。
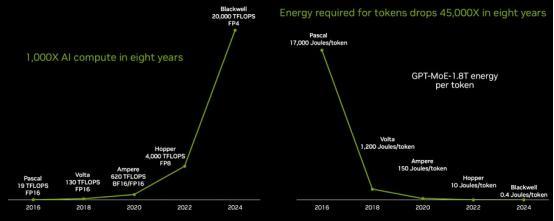
英伟达的GPU架构从Fermi到 Hopper再到Blackwell,每次架构升级都带来性能和能效上的显贵培植。从“Pascal” P100 GPU一代到“Blackwell” B100 GPU 一代,八年间GPU 的性能培植了1,000多倍。天然昔时八年性能培植了1000多倍,但是GPU的价钱仅飞腾了7.5倍。据了解,Nvidia的新款基于Blackwell的GB200 GPU系统粗略以比上一代H100系统的推理速率快30倍,但与H100 初次发布时的价钱大致不异,预测每台GB200 GPU 的售价在30,000至40,000好意思元之间。
从Hopper GPU开动,英伟达就一直属于抢手货,而新一代的Blackwell亦是如斯。10月,英伟达CEO黄仁勋示意,最新的Blackwell GPU翌日12个月的订单均一经售罄,AWS、Google、Meta、Microsoft、Oracle 和CoreWeave等主要科技巨头是大买手。
由于对数据中心GPU的需求,Nvidia的市值自2023岁首以来增长了近十倍。2023岁首,英伟达的市值为3600亿好意思元。不到两年后,其市值已卓绝3.4万亿好意思元。
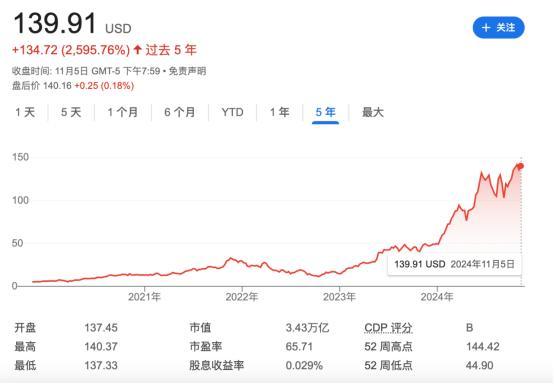
Nvidia市值超越苹果成为环球最有价值的公司
GPU边界的发展速率之快是前所未有的,就拿AMD来说,在 AMD 2024 年第三季度财报电话会议上,AMD CEO Lisa Su指出,其GPU销量已接近CPU销量,这点与AMD涉足AI阛阓大联系连。AMD的AI GPU业务才刚开动一年,营收就一经快达到CPU业务边界。在财报会上,Lisa Su还示意:“仅在数据中心,咱们预测AI加速器阛阓边界将以每年60%以上的速率增长,到2028年将达到5000亿好意思元。这大致很是于2023年统统这个词半导体行业的年销售额。”AMD将2024年GPU销售额预测从45亿好意思元上调至50亿好意思元以上。
但是,GPU这么的快速发展也带来了新问题。跟着GPU性能的控制培植,背后支捏它们的基础方法——尤其是互联时刻和存储时刻——却显得相对滞后。
跟不上的互联时刻
如今,大型说话模子(LLMs)如ChatGPT、Chinchilla 和 PALM,以及保举系统如 DLRM 和 DHEN,都在雨后春笋的 GPU 集群上进行考研。考研进程包括频繁的筹划和通讯阶段,互联时刻就显得尤为关节。
传统的互联时刻如PCIe(外围组件互联)接口的带宽已难以守旧日益增大的数据传输需求,也早一经跟不上GPU的速率,PCIe法式天然缓缓演进,但它的传输带宽与GPU处明智商之间的差距越来越大。特殊是在多卡并行筹划的场景中,PCIe显得纳履踵决,功令了GPU的最大性能开释。尽管咫尺许多大公司尝试承袭法式PCIe交换机,并通过基于PCIe的结构膨大到更多加速器,但这仅仅权宜之策。
为了支吾这一瓶颈,英伟达开发了自家的高速互联时刻——NVLink和Infiniband。NVLink 时刻可用于 GPU 之间的高速点对点互连,提供高带宽和低延伸的数据传输,并通过 Peer to Peer 时刻完成 GPU 显存之间的径直数据交换,进一步镌汰数据传输的复杂性。这关于漫步式环境下运行的复杂 AI 模子尤为要紧。更快的纵向互联有助于管事器集群内每个 GPU 性能的充分开释,从而培植合座筹划性能。

开始:Nvidia
至于Infiniband时刻,是一种收罗流畅时刻。英伟达于2019年收购了Mellanox Technologies,Mellanox是环球率先的InfiniBand时刻提供商之一。收购后,英伟达链接鼓舞InfiniBand时刻的翻新,并在其加速筹划平台中深度集成了InfiniBand收罗。天然以太网(Ethernet)在好多应用中是主流的收罗流畅时刻,但在高性能筹划(HPC)和AI考研等场景中,InfiniBand相较于以太网,具有显贵上风:它提供更高的带宽、更低的延伸,且原生支捏长途径直内存打听(RDMA),使得数据传输愈加高效。

Nvidia的Quantum-X800 InfiniBand(开始:Nvidia)
而AMD则推出了我方的Infinity Fabric互联时刻,专为数据中心优化,旨在培植数据传输速率和镌汰延伸。不外Infinity Fabric天然亦然比不外NvLink的,否则AMD也不会发起UALink定约。
NVLink和InfiniBand时刻天然具有昭彰上风,但它们都是英伟达的独到时刻。跟着行业对互联时刻需求的控制增长,一方面但愿幸免英伟达在时刻上的左右,另一方面也濒临着互联时刻瓶颈的挑战。因此,许多企业开动对标英伟达的互联时刻,尝试开发替代决议。
客岁7月19日,超等以太网定约 (UEC)提拔,来对标InfiniBand。创举成员包括AMD、Arista、Broadcom、念念科、Eviden(Atos 旗下企业)、HPE、英特尔、Meta 和微软。咫尺超等以太网定约一经眩惑了67家公司的加入。其中不乏有许多初创公司,定约的提拔将使这些初创公司从该定约的举措中受益良多,UEC将成为初创公司在优化 TCO 的同期独霸复杂的AI和HPC收罗模式的关节。

UEC部分会员一览(开始:UEC官网)
本年,行业再度将锚头瞄向于NVLink。本年10月,由AMD主导,九大行业巨头——包括AMD、英特尔、Meta、惠普企业、亚马逊AWS、Astera Labs、念念科、谷歌和微软——持重计议提拔了UALink(长入加速器互联)。UALink的见识是成为AI加速器膨大流畅的行业通达法式。其主要上风在于,UALink为复制NVLink和NVSwitch功能并与其他公司分享开发遵循提供了一条门道,从而让统统这个词行业的其他参与者都有契机与NVIDIA保捏递次一致。
UALink 1.0表率将于本年向会员通达。该法式将为AI pod内多达1,024个加速器已毕高达每通谈200Gbps的流畅。假定 Nvidia HGX 立场的管事器里面有 8 个 AI 加速器,UALink 不错在一个pod中流畅多达 128 台这么的机器。据tomshardware的报谈,不外,UALink 最有可能无为以较小的边界使用,大要8个管事器的pod通过UALink相互通讯,进一步的升级由超等以太网处理。定约成员将在本年取得该表率的打听权限,并于 2025 年第一季度开动进行全面审查。
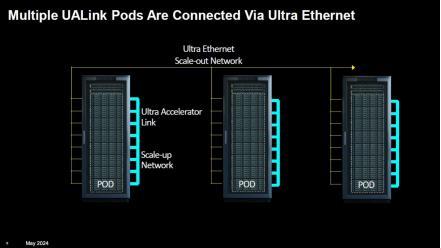
开始:UALink新闻简报
岂论是NVLink、Fabric照旧UALink,这一系列举措反应出,现存的互联时刻跟不上加速器发展速率的广宽问题,行业伏击需要新的处罚决议来支捏更强劲的算力需求。
存储更贫穷
与互联时刻的滞后比较,存储时刻的越过似乎显得愈加贫穷。在AI、机器学习和大数据的推动下,数据量呈现出指数级的增长,存储时刻必须紧随自后,才调确保数据处理的遵循和速率。关于刻下的内存行业来说,高带宽内存(HBM)一经成为焦点,尤其是在大模子考研所需的GPU芯片中,HBM险些一经成为标配。
GPU依赖于高带宽内存(HBM)来满足高速数据交换的需求。与CPU比较,GPU需要愈加频繁的内存打听,且数据的打听模式具有很高的并行性。这条目存储系统必须粗略在毫秒级的延伸内提供极高的数据带宽。
2013年,SK海力士推出了首款HBM芯片,直到大模子的崛起,HBM才着实迎来了应用的黄金时机。频年来,SK海力士加速鼓舞HBM时刻的更新迭代。本年9月,SK海力士得胜批量坐蓐了环球首款12层HBM3E家具,并打算于2025岁首推出首批16层HBM3E芯片样品。正本预测在2026年量产的HBM4,SK海力士已将期间表提前,预测将在2025年下半年委派12层HBM4芯片。
尽管如斯,黄仁勋仍在敦促SK海力士加速HBM4的供应,初步条目提前6个月委派。天然HBM的需求火爆,存储厂商依然濒临着坐蓐智商、时刻瓶颈和老本等多重挑战。
存储时刻的滞后给高性能筹划带来了多重挑战:
筹划智商谮媚:GPU的矫捷筹划智商无法得到充分运用,存储瓶颈导致多半的GPU筹划资源处于优游情状,无法高效地试验任务。这种不匹配导致了系统性能的低效进展,加多了筹划期间和能源顿然。
AI考研遵循下落:在深度学习考研进程中,多半的数据需要频繁地在GPU与存储之间交换。存储的低速和高延伸径直导致AI考研进程中的数据加载期间过长,从而延长了模子考研的周期。这关于需要快速迭代的AI形状来说,尤其是营业应用中,可能会酿成较大的老本压力。
大边界数据处理的挫折:跟着大数据的兴起,许多AI应用需要处理海量数据。刻下存储时刻未能有用支捏大边界数据的快速处理和存储,特殊是在多节点漫步式筹划的场景中,存储瓶颈时时成为数据流动的最大挫折。
为了处罚存储跟不上GPU发展的瓶颈,业界一经提议了一些潜在的处罚决议:举例存算一体以及CXL这么的智能存储架构。
跟着处理在内存(PIM)时刻的兴起,筹划和存储有可能进行更精细的集成。PIM时刻允许筹划任务径直在存储迷惑上进行处理,幸免了数据在筹划和存储之间的传输瓶颈。此类时刻有望大幅培植存储系统的性能,并有用支捏GPU等筹划芯片的高速数据打听需求。
智能存储架构:通过承袭更智能的存储架构,如CXL(Compute Express Link)和NVMe合同,不错已毕更高效的存储膨大和更低延伸的数据打听。CXL提供了筹划和存储之间的高速互联,使得GPU粗略更快速地打听存储数据,处罚传统存储架构中存在的带宽瓶颈问题。
存储时刻滞后于筹划芯片发展的风光,昭着一经成为当代筹划系统中的瓶颈。尽管存储时刻一经取得了一些进展,但与GPU等筹划芯片的快速发展比较,仍存在较大的差距。
转头
在咫尺快速演变的时刻生态系统中,多时刻协同升级已成为推动新兴时刻发展的中枢能源。要已毕算力的捏续增长,GPU、互联、存储等时刻必须协作发展。天然GPU时刻已取得了显贵越过,但莫得更高效的互联时刻和更快的存储时刻守旧,算力的后劲将无法都备开释。
关于英伟达等科技巨头而言,如何链接推动GPU与其他关节时刻的协同进化,处罚存储、互联的瓶颈,将是翌日几年中的主要挑战。
本文来自微信公众号“半导体行业不雅察”(ID:icbank)开云网页版登录(官网)登录入口,作家:杜芹DQ